

Introdução
Quando começamos a estudar microsserviços, são nos apresentados muitos conceitos, padrões, protocolos e ferramentas diferentes, tais como Messaging, AMQP , RabbitMQ , Event-sourcing , gRPC , CQRS e muitos outros. Entre tantas palavras diferentes e no que diz respeito à comunicação entre serviços, há uma que sempre chamou a atenção e que seria perfeita para os desafios que enfrentamos na VOID, o Apache Kafka.
O que é Apache Kafka?
Uma plataforma de streaming distribuída.
Então, basicamente, Kafka é um conjunto de máquinas trabalhando juntas para ser capaz de manipular e processar dados infinitos em tempo real.
Embora o Kafka tenha começado como um sistema de mensagens de publicação-assinatura (semelhante a filas de mensagens ou sistemas de mensagens corporativas, mas não exatamente), ao longo dos anos ele se desenvolveu como uma plataforma de streaming completa.
Basicamente, possui 3 componentes principais.
- O principal componente do Kafka: o sistema de mensagens publicar-assinar, que pode armazenar (não como um banco de dados) fluxo de dados com tolerância a falhas.
- Kafka Streams API: permite que um aplicativo atue como um processador de stream, que pode consumir um stream de dados de tópicos Kafka (1 ou mais), transformá-lo e produzir a saída de volta para os tópicos Kafka. Utilizando o KSQL, você também pode consultar tecnicamente os dados nos fluxos.
- Kafka Connect: permite a persistência dos dados nos tópicos Kafka num banco de dados ou num dos muitos suportados coletores, ou ler dados de uma fonte e gravar num tópico Kafka. Digamos que precisamos ler dados do banco de dados Oracle, conector de origem JDBC ou gravar dados em S3 dos nossos tópicos Kafka: conector S3.
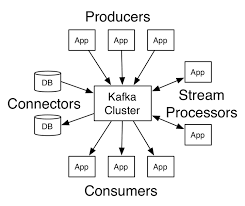
A sua arquitetura distribuída é um dos motivos que tornou Kafka tão popular. Os Brokers é o que o torna tão resiliente, confiável, escalável e tolerante a falhas. É por isso que Kafka é tão performático e seguro.
Neste artigo vamos cobrir apenas o principal componente de Kafka. Falaremos sobre Kafka Connect e Kafka Streams num outro dia. Para isso, precisamos entender algumas terminologias Kafka.
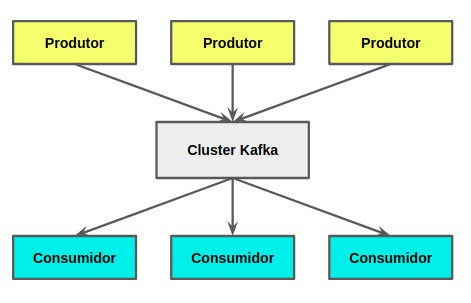
1. Produtor: é apenas um aplicativo que enviaria dados ou mensagens para o cluster Kafka. Não importa quais dados enviamos, é apenas um array de bytes para Kafka. Digamos que tem uma tabela de pedidos no seu banco de dados, cada linha na sua tabela corresponderia a uma mensagem e você usaria a KafkaAPI do produtorpara enviar as mensagens para o tópico Pedidos.
2. Consumidor: é mais um aplicativo que iria ler/consumir dados do cluster Kafka. O único problema aqui é que o aplicativo não consome os dados diretamente de um produtor. Em vez disso, a mensagem é enviada aos corretores (brokers) Kafka e os consumidores assinam um tópico. Digamos que precisamos processar os dados dos pedidos, podemos apenas consumir fora do tópico “Pedidos” usando a API do consumidor Kafka.
3. Tópico: é mais um aplicativo que iria ler/consumir dados do cluster Kafka. O único problema aqui é que o aplicativo não consome os dados diretamente de um produtor. Em vez disso, a mensagem é enviada aos corretores (brokers) Kafka e os consumidores assinam um tópico. Digamos que precisamos processar os dados dos pedidos, podemos apenas consumir fora do tópico “Pedidos” usando a API do consumidor Kafka.
4. Broker: Broker (ou corretor) é o cluster Kafka onde os dados reais residem. Como o cluster Kafka atua como um intermediário entre o produtor e o consumidor, ele é chamado de corretor.
5. Cluster Kafka: é apenas um conjunto de corretores Kafka acoplados ao registro Zookeeper e Schema (geralmente, mas não necessariamente).
6. Partições: cada tópico do Kafka é dividido em partições. Esta é a unidade de paralelismo em Kafka. Os dados em cada partição são ordenados com base no tempo. Temos que decidir o número de partições de que precisamos para o nosso tópico durante a sua criação. Os dados sobre os tópicos do Kafka não são mantidos para sempre, eles têm uma política de retenção (padrão: 7 dias), mas você pode aumentar o tempo de retenção.
Quando temos mais de 1 partição, os dados são divididos entre as partições e espalhados por vários brokers. Além disso, a ordem não é garantida entre as partições (temos que fazer algum trabalho extra para conseguir isso). Isso significa que o Kafka não garante que a mensagem m9 no deslocamento 9 da partição 1 tenha chegado antes da mensagem m12 no deslocamento 12 na partição 0. Mas garante que a mensagem m11 no deslocamento 11 atingiu o Kafka antes de m12 no deslocamento 12 na partição 0.
7. Offset: Offset é apenas um id de sequência crescente dado a cada mensagem dentro de uma partição na ordem de chegada. Eles são sequências imutáveis a partir de 0 em cada partição.
8. Grupos de consumidores: são os grupos de consumidores que distribuem os dados que precisam ser consumidos dentro do grupo.
Em jeito de conclusão, podemos dizer que Kafka é uma das ferramentas mais completas e executivas que temos hoje. Depois de estudá-lo e obter seus principais conceitos, percebemos que é muito mais do que um sistema de mensagens. Sua arquitetura distribuída e processamento em tempo real são o que o torna tão adaptável a cenários e casos de uso muito diferentes.
É por essa razão que na VOID estamos a desenvolver soluções baseadas em sistemas distribuídos, altamente resilientes e escaláveis, suportadas por Kafka. Especialmente quando o nosso objectivo é criar soluções pensadas para o mercado africano e global.


